The class methodology presented in this chapter is the core methodology presented in this book. It solves the data hiding problem. You will produce code that contains fewer bugs by using this methodology because it prevents and detects bugs. The class methodology helps to prevent bugs by making it easier to write C code. It does this by eliminating data structures (class declarations) from include files, which makes a project easier to understand (because there is not as much global information), which makes it easier to write C code, which helps to eliminate bugs. This class methodology, which uses private class declarations, is different from C++, which uses public class declarations. The class methodology helps detect bugs by providing for both compile-time and run-time type checking of pointers (handles) to class objects. This run-time type checking catches a lot of bugs for you since invalid object handles (the cause of a lot of bugs) are automatically detected and reported. All the code introduced in this chapter can also be found in one convenient location in the Code Listings Appendix. 4.1 The Problem with Traditional Techniques 4.1.1 Data Structures Declared in Include Files The problem in a lot of projects is the number of data declarations in include files. Consider what happens when a small project grows gradually into a large project. In the small project, you have a small team of programmers who all know the project reasonably well. Each person is contributing code as well as data declarations. Some new data declarations undoubtedly refer to previous data declarations. This methodology works fine for small isolated projects. What happens as the project grows and more programmers are added to the project? The old programmers continue to code as they always have. The new programmers have a steep learning curve. In order for them to become productive on the project, they first have a lot to learn about how it works. When the new programmer does come up to speed on the project, you now have one more programmer adding information to the pool of information that must now be learned by everyone. It does not take too long before your pool of information is so large and interconnected that it becomes impossible for any one person to fully understand the project as a whole. At this point, the next logical step is to have individual programmers within the group specialize in a particular area of the code or project. This division of labor can be implemented successfully, but too often it just creates isolated groups with little communication and very little code sharing among groups. The single biggest problem with any large project is that data structures are declared in include files. Any programming methodology that attempts to solve the information overload issue must also address data structures declared in include files. 4.1.2 Directly Accessing Data Structures Once data structure declarations are placed into include files, those declarations become public knowledge. Do you consider this a good or a bad thing? What are the pros and cons? The pros and cons of public data structures depend totally upon the size of the project. For small projects isolated to one programmer, public data structures can actually speed up the development time of the project. However, for any moderate to large project, with no matter how many programmers, public data structures quickly becomes a bad thing. The primary problem with public data structures is that they promote writing code that directly accesses the data structure instead of calling a function that manipulates the data item. This direct access is bad because the distinction between the implementor of the data object and the user of the data object becomes totally blurred. This blurring between the implementor and user of a data object over time leads to a project that is impossible to modify in any way. Just think what would happen if the data object needed to be changed to support a new feature. All code that directly accesses that data object would have to be changed. This is obviously very undesirable. 4.1.3 Compilation Times Another problem with public data structures is the time needed to compile source files whenever any change is made to a public structure. Any change to the structure may force you to recompile every source file that references the data structure. Determining this set of files is not always easy and to avoid possible problems you end up compiling the entire program. This actually works quite well for small projects, but what about large projects? What about large projects under version control software? Complete builds of a project may take anywhere from several minutes to several hours. The ideal situation that you should strive for, if at all possible, is a one-to-one dependency between data structure and source file. In other words, a change to a single data structure should require, at most, one source file to be recompiled. 4.2 The New Object Model Any solution to the information overload problem must address two key issues involving data structure declarations: Where are data structures placed? How are data structures accessed? 4.2.1 Terminology Before continuing, some terms need to be defined. An object is any data declaration. A method is a function that acts upon an object. A handle is an abstract object identifier. An instance is a unique occurrence of an object that occupies space in memory. 4.2.2 Private Objects and Public Methods The traditional software development approach is one of public access to objects and public methods. To manipulate the object, you either directly access the object or you call one of the methods of the object. The new object model I propose is one of private access to objects and public methods. The only way to manipulate an object is by calling one of the methods of the object. This implies that an object has a minimum of two method functions: one method function to create an instance of an object and another method function that destroys an instance. Private access and public methods also imply that an object's data declaration and method functions are contained in the one source file that implements the object and not an include file. Private objects is just another term for complete data hiding. The data of an object is visible only to the implementor of the object and not to the user of the object. If this object model can actually be implemented, it will solve the two key issues involving data structure declarations. Where are data structures placed? (in source files, not include files). How are data structures accessed? (privately -- only through method functions). Let me relate the problem to the real-world problem of generating random numbers. The standard C library routines provide one global random number generator with functions or methods to seed and return the next random number. These functions are srand() and rand(). How would you extend this model to provide multiple independent random number generators? One simple extension would be to add another argument to srand() and rand() that specifies which random number generator to use out of a static array of possible generators. While this design does work, it has several problems. All code that uses the new random number generator interface must cooperate on which indexes to use. What if the random number generator code is in a Windows DLL, which any number of applications can link to and use? Again, all these applications must cooperate on which indexes to use. The static array implementation also imposes a fixed maximum to the number of random number generators that can be used. Therefore, a static array is a bad implementation choice for a generalized object model. What this means is that you need an object model that supports dynamically allocated memory. In terms of the random number generator, you need a data structure containing the data needed to implement the random number that is created and destroyed as needed. The method functions srand() and rand() then operate upon this dynamically allocated data structure. Creating and destroying objects as needed is also much better than static arrays because all objects now share all available memory. This means that your program is not limited by some arbitrarily picked array bounds but instead by how much memory there is.
4.3 Compile-Time Type Checking We have a requirement for an object model in which there are private objects and public methods that act upon the objects. So how are handles to private objects going to be type checked? Remember, the object is private and the compiler is doing the type checking in modules that do not have access to the object's data declaration. All objects are dynamic and every object type in the system has at least two method functions. One method creates an object, returning a handle to the object, and another method destroys the object. A handle could be an index into an object table. It could be a near pointer into a private heap. It could be a long pointer to the object. It could also be a global memory handle in which the object is contained. The point is that the user of a handle does not know and does not need to know exactly what a handle is. To be consistent, however, all objects in an object system usually produce the same type of handle. This prevents some handles from being indexes and some from being memory pointers, which would only confuse the situation. 4.3.1 The Problem There are almost unlimited numbers of ways to implement this object system except for the requirement that object handles must be type checkable by the compiler. This obviously implies that a handle must be some data type, because only data types can be type checked by the compiler. If an object's data structure declaration is private and declared and known only to the one source file that implements the object, how in the world are you going to get the compiler to perform type checking on handles to this object in other source files? 4.3.2 The Breakthrough The breakthrough in accomplishing this complete data hiding while still maintaining compiler type checking came after I realized how to get the C compiler to perform type checking on pointers without knowing what the pointer points to. In other words, it is possible to create a pointer in C that points to an unknown object and yet is type checkable by the compiler. It is also impossible to perform an indirection on this pointer in all source files except in the one source file that implements the object, where an indirection is possible. Does this sound too good to be true? The remarkable part about this feature of the C language is that you probably have used this feature but never fully realized its potential. Consider how you would implement a linked list of nodes.
The solution is to use structure tags. Because PNODE does not even exist when you want to declare pNext, it is declared as a pointer to struct tagNODE. Consider how you would implement two structures that contain pointers to each other.
Take a close look at this example. In it you see that pNodeB is being declared to be a pointer to a structure tag, a structure that does not yet exist. This example can be rewritten as follows.
In this example, PNODEA is a type that points to struct tagNODEA and PNODEB is a type that points to struct tagNODEB. PNODEA and PNODEB are then used even though the structure declarations do not exist yet. Structure tags allow you to create a pointer to an object before the object even exists and perform type checking on the pointers. In fact, the pointer declarations could have been placed in an include file and used by other source files. As long as the other source files do not try to perform an indirection on the pointer, everything works. Then in the source file with the structure declaration (with the appropriate structure tag) pointer indirections have meaning. Pointer indirections have meaning when they appear in a source file that has a structure declaration with the appropriate structure tag. 4.3.3 NEWHANDLE() Macro Now that we know this, we can write a macro that introduces new type checkable handles into the programming environment.
The NEWHANDLE() declarations are almost always placed in an include file that gets included into all source files. NEWHANDLE() is usually not used in source files. Notice in NEWHANDLE() how the token pasting operator (##) is being used in tag##Handle to create a structure tag that is derived from the handle name. By convention, all handle types must be in uppercase and prefixed with the capital letter H (HRAND, for example). If your C environment does not support the token pasting operator, but your preprocessor follows the Reiser model, you can still accomplish token pasting. See §2.2.8 for details. This technique involves replacing ## with /**/. Going back to the random number generator example, creating a handle called HRAND would now be easy.
So, HRAND is really just a pointer to an unknown structure whose structure tag is tagHRAND. The HRAND type can be used even though no structure with a structure tag of tagHRAND exists in the modules being compiled. This is just like the linked list of nodes with the PNODEA and PNODEB types. A complete random number generator interface specification in an include file could quite possibly be written as follows.
It is important to realize how the HRAND data type works. Immediately after the NEWHANDLE(HRAND) declaration, HRAND can be used just like any other data type except that it cannot be dereferenced because what HRAND really is is not yet known. In other words, HRAND can be used in function prototypes and HRAND variables can be initialized and passed around, but trying to dereference the HRAND variable will not be possible. Consider some code that needs its own random number generator. It creates one using RandCreate(), uses it by calling RandNext() and when finished, calls RandDestroy(). The code is able to use HRAND without knowing what HRAND points to. There can also be an unlimited number of random number generators active at any given time.
It is important to realize how the HRAND data type is working in Testing(). The Testing() function is using an HRAND variable hRand even though Testing() has no idea what hRand points to or how the HRAND data type is implemented. In fact, the HRAND structure declaration is not even visible to this Testing() function. This is because HRAND at this point is a pointer to an unknown, but named (tagHRAND), object/structure. Notice the spelling of hRand. It is an upper- and lowercase variant of its data type, HRAND. You should always try to derive object variable names from object data types this way. The only source line that may not be totally clear in Testing() is the hRand=RandDestroy(hRand); line. By convention, all functions that destroy an object return the NULL object, so this ends up setting hRand to NULL. The reasoning behind this is that you always want a handle variable to contain a valid handle or NULL. You never want a handle variable to be uninitialized or contain an old, previously valid, handle (see §7.12 for more information on the usage of NULL). 4.3.4 Implementing the Random Number Generator There are still a lot of loose ends to fully implement the random number generator, but here is a rough shell of what the code will look like.
The struct tagHRAND structure declaration is declared in the source file that implements HRAND and not in an include file. The implementation is straightforward. The details of random number generation in the NEXTRAND() and FINALRAND() macros and how memory is allocated and freed for the objects has been left out. This is discussed later. The only catch is TYPEDEF. For standard C, TYPEDEF is defined to be typedef. For C++, TYPEDEF is defined to be nothing. This was done to avoid the Microsoft C8 warning message C4091 no symbols were declared under C++. In the struct tagHRAND declaration, a declarator is not required after the ending brace and before the semicolon because a structure tag is being used. When a structure tag is used, the declarator is optional. Without a structure tag, the declarator is generally required. This has to do with how C works and it is spelled out in §A8 of The C Programming Language. This random number generator source is contained in its own source file. It is important to realize this. This code need not and should not be declared along with other code, like the Testing() function, that uses the random number generator. The implementation of an object should be contained in a separate source file and a source file should implement, at most, a single class object. This implementation is in its own source file and #includes the same include file that all other source files include. This include file contains the NEWHANDLE(HRAND) declaration and function prototypes. Even in the source file that implements the HRAND object, the compiler has no idea what HRAND is until a structure is declared with a structure tag of tagHRAND. At this point, the compiler binds what HRAND is to the tagHRAND structure and indirections are now possible. In other words, as soon as this binding of HRAND to the structure with tag tagHRAND takes place, we are free to implement the HRAND object because indirections on the object are now possible. 4.3.5 Summary The problem in an object model with private objects is getting the compiler to type check pointers to the objects when the objects are not even known to the compiler. The solution is to use an incomplete type, a feature of C. A handle to an object is a pointer to a structure that has a structure tag, but a structure that does not have a body. This incomplete type allows the compiler to perform type checking on a pointer to the structure when the structure is not known. The NEWHANDLE() macro introduces a new type checkable handle into the system. 4.4 Run-Time Type Checking An important part of any object system is to provide as much error detection and reporting as possible. A common mistake that all C programmers make is accidentally passing an incorrect value to a function. In the case of handles, which are simply memory pointers, passing an incorrect value to a method function may or may not have unpredictable results because the memory pointer may just happen to be valid (but pointing to the wrong memory location). Ideally, passing an incorrect pointer to a method function causes some sort of protection fault which would allow you to track down the problem. What if using an incorrect pointer does not cause a fault? The method function more than likely ends up trashing memory instead; in any case, it will not perform the function the caller intended. A prime example of how this can happen is using an object handle after the object has been destroyed. The memory pointed to is more than likely still addressable, but there is no valid object in the memory. Another example is memory that has been accidentally overwritten. If the memory contains any object handles, those object handles are now invalid. By far the most common memory overwrite is writing beyond the end of a character array. Detecting this is discussed in Chapter 5. The first line of defense against incorrect handles is to have the compiler perform type checking on the handles. This makes it almost impossible at compile-time, except through type casting, to pass an incorrect handle to a method function. The second line of defense is to have every function that accesses an object verify that the object is an object of the correct type at run-time. In our new object model, the functions that access the object are the method functions, all of which are contained in one source file. Because all the method functions are localized to one file, this opens up interesting optimization possibilities in performing run-time type checking. 4.4.1 Requirements Adding run-time type checking into a system is not a new idea nor is it a hard thing to do. However, adding it into a system almost transparently is a challenge. Low overhead. The first requirement is that run-time type checking must have a minimal impact on the execution time of a program. A 1 percent or less impact would be great. A 10 percent impact would be substantial, but it could be justified. Fault-tolerant code execution. Any syntax we come up with must be able to support conditional execution of a section of code. If the run-time object verification succeeds, you want the code to execute. If the verification fails, you do not want the code to execute. What good would it be to have a system that notifies you of an object verification failure only to bomb a split second later on code that expected a valid handle but did not have one? Automatic and easy to use. Any system that we come up with must not require a lot of work on the part of the programmer. The goal is to make the programmer's job easier, not harder. Minimal code and syntax changes. Again, we do not want to create a system that is hard for the programmer to use. Any system we come up with must not require a lot of code changes. Does not change the sizeof() an object. A system that changes the sizeof() an object simply because it is being type checked is undesirable and should be avoided. Must itself not cause crashes. This may seem obvious, but a system must be able to withstand any address passed to it for verification, even addresses that are invalid. It is not enough to simply verify that an object at a valid address is the correct object. It must also make sure that the address itself is valid before attempting to validate the object. This is hard to implement since it requires explicit knowledge of the memory architecture of the hardware you are running on. Withstands implementation changes. We do not want the run-time type checking to be hard-coded. Instead, it should be isolated through the use of macros. This allows the run-time type-checking implementation to radically change with no source code changes in the modules that use run-time type checking. 4.4.2 What to Use for Data Type Identification There appears to be a contradiction in the requirements section. How can type checking be added to an object and not have the object change size? The solution is to let the layer beneath the objects keep track of object types. This layer is the heap manager and, as we found out earlier, the standard heap management routines are not robust enough and would have to be replaced anyway. Why not, then, just add one more argument to the memory allocation routine that indicates the type of the object being allocated? This covers all instances of objects in the class methodology, since all objects are dynamically allocated in the heap. The big question now is what to use to indicate the type of an object. We could use a unique integer value, but this is not automatic. It requires the programmer to maintain the list of IDs. Worse yet, in a shared DLL situation, the programmer likely has multiple applications using the same DLL, so what unique integer values are used in this case? Now all applications need to cooperate on the IDs to use. Since this is undesirable, unique integer values will not work.
The goal is to have the object system automatically determine the type identifier of an object. One possible solution would be to have the heap manager generate unique type IDs at run-time as needed. While this would certainly work, there is a much better way. Remember that the entire goal is to come up with any guaranteed unique number as the type identifier. Why not just use the address of nTypeOfHRAND as the type identifier! The address is absolutely unique. In fact, you could use the address of anything that is uniquely associated with the class object. So, we will create a class descriptor structure that contains information about a class object and use its address as the type identifier. There will be one class descriptor per class.
Associating the variable name typically used for instances of a class is a valuable piece of information to associate with the class description. This is done with the lpVarName member of the CLASSDESC structure. This allows the custom heap manager to produce symbolic dumps of the heap, complete with variable names used in the code. How are these class descriptors going to be named? 4.4.3 Naming Class Descriptors The class descriptor address is needed during run-time object verification and it is needed when the object is created. Is there a way that its address can be obtained automatically, without having to specify the actual address by explicit reference? Consider the random number generator example. The data type is HRAND and instance variables are named hRand. We want to run-time type check the variable name hRand, not the data type HRAND. Provided the class descriptor name contains hRand, the address of its class descriptor can be determined automatically! How? Through the use of the C preprocessor token pasting operator. We now need a macro that, when given a variable name, provides us with the name of its class descriptor. The _CD() macro does this for us.
Notice in _CD() how the token pasting operator (##) is being used in hObj##_ClassDesc to derive the class descriptor name from the object name. The _CD() macro begins with a underscore character. This indicates that the macro is to be used only in other macros, not in source code. See §3.4.1 for more information on naming macros. Basing a class descriptor name on an object's variable name instead of the object's data type is a powerful concept. It allows us to write macros that are object-based. The only piece of information needed is the actual variable name. All other information can be obtained from the class descriptor.
In the case of the hRand object, the class descriptor for hRand is named hRand_ClassDesc. We are now ready to allocate and initialize the class descriptor. 4.4.4 The CLASS() Macro The class descriptor structure used for run-time type checking needs to be allocated and initialized once. There is one class descriptor per class. It makes a lot of sense to do this at the same place in the code where the class structure is being declared. The class descriptor for the random number generator object would look like the following.
We can now design a macro that performs all of class descriptor and structure declaration dirty work in one step.
The CLASS() macro is used only by source files that implement an object. The CLASS() macro is never used in include files. The CLASS() macro takes two arguments. The first argument is the variable name that is used to represent instances of objects of this class. The second argument is the handle name of the class objects. The class descriptor is allocated and initialized based upon the variable name and the stringizing operator (i.e., #hObj). The structure declaration is started based upon the handle name (i.e., TYPEDEF struct tag##Handle). Allocating memory for a class object based upon its variable name now becomes incredibly simple. In the case of an hRand variable name, the number of bytes that need to be allocated is sizeof(*hRand) and the type information address is &_CD(hRand). We are now ready to implement run-time type checking. 4.4.5 The VERIFY() Macro Given any valid variable name that is a handle to an object, an ideal syntax for the run-time object verification macro would be as follows.
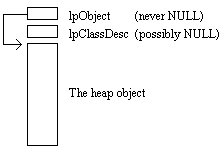
The VERIFY() macro is designed to be used only by the source file that implements an object, not by other source files that just use an object. At the core of the VERIFY() macro is its usage of WinAssert() §3.3. This allows VERIFY() to be terminated with either a semicolon or a block of code. Again, notice that the only piece of information needed is the object's variable name. No other information needs to be provided. The VERIFY() macro implements the syntax that is desired but leaves the implementation to another macro called _VERIFY(). The VERIFYZ() macro is a slight variation on the VERIFY() macro. If a NULL pointer is passed to VERIFYZ(), the optional body of code is not executed, nor is this treated as an error. VERIFYZ() is useful in allowing NULL pointers to be passed to an object's destroy method. Given a handle to an object, which is just a pointer to the object, you should be able to obtain information about the object maintained by the heap manager. As we will see in Chapter 5, the heap manager just provides a wrapper around the object. This means that the heap manager's information about the object can be accessed by using negative offsets from the object pointer. For speed, these offsets are known by both the heap manager code and the run-time object verification code. (See Figure 4-1). The data item immediately before a valid heap object is a long pointer to the class descriptor of the object or NULL, which indicates that no class descriptor exists. The data item before the class descriptor pointer is a pointer to the heap object, which is used for heap pointer validation. Using hRand as an example, the steps needed to verify that the address contained in hRand does indeed point to a valid random number object are as follows. 1. Is hRand a valid pointer into the heap? This step is the most difficult since it depends upon the machine architecture that the program is running on. More on this later, but for now we will use FmIsPtrOk(hRand). 2. Does the address in hRand match the address at hRand minus two data items? Namely, (((LPVOID)hRand)==*(LPVOID FAR*) ((LPSTR) hRand-sizeof(LPCLASSDESC)-sizeof(LPVOID))). 3. Does the address at hRand minus one data item match &_CD(hRand)? Namely, ((&_CD(hRand))==*(LPCLASSDESC FAR*)((LPSTR)hRand-sizeof(LPCLASSDESC))). One possible _VERIFY() macro implementation is as follows.
To be efficient, the _VERIFY() implementation must be tailored to a specific development environment. It also assumes that an effective FmIsPtrOk() can be written. This will be discussed in Chapter 5. I have found out over the years that the source code has stayed the same, but the _VERIFY() macro implementation keeps on changing to suit my development environment. My development environment was once based upon the small memory model of the Microsoft compiler. Then it moved to the medium memory model; then to a based heap allocation scheme and finally to a model in which data is kept in far data segments. Through each of these changes, the code has stayed the same, but the _VERIFY() implementation has changed quite a bit. I cannot provide you with a generalized _VERIFY() implementation. You must code a _VERIFY() that works in your particular environment. The _VERIFY() that I use in my environment follows.
4.4.7 Summary The CLASS() and VERIFY() macros work together to provide what is needed to run-time type check object handles. The stringizing operator and the token pasting operator are key features of C that make these macros so easy to use. 4.5 Managing Memory What should be the interface for allocating and freeing objects? The interface should probably be implemented through a set of macros to allow the implementation to change without having to change any source code. 4.5.1 NEWOBJ() and FREE() Interfaces A model for allocating an object is NEWOBJ(hObj). The NEWOBJ() macro implementation should do all the dirty work of allocating the memory from the heap manager, passing the appropriate type information and assigning the memory pointer to hObj. A model for freeing an object is FREE(hObj). It should call the heap manager to free the memory associated with hObj. It should also ensure that hObj is set to NULL as well. This allows us to find any bugs that involve using the handle after calling FREE(), because dereferencing a far NULL pointer causes a CPU fault to occur in protected-mode architectures. See §7.12 for more information on using NULL. However, before we can write these macros, the interface to the new heap manager must be specified. 4.5.2 Heap Manager Interface Specification Because the heap manager is at the core of the object management system, it should have as much error checking information available in it as possible. One piece of information we already know it must have is the address of a class descriptor. Since this allows us to write a heap manager that provides great symbolic dumps of the heap, why not add some more information that would be meaningful in the heap dump? Why not include the filename and line number where the object was allocated? This information is useful for non-object heap objects like strings. The reason that it is not as useful for objects is that objects are created only in one method function. Another concern is which memory model to use for heap objects. For specialized applications, this is of major concern since the memory model affects the performance of the application. However, for the object model, an interface that uses 32-bit pointers is assumed. The 32-bit address may be a segment and offset for segmented architectures, or it may be a linear virtual address in flat-model architectures. Whichever architecture it is, it does not matter.
The FmNew (far memory new) takes four arguments. The first argument indicates the number of bytes to allocate in the object. It is of type SIZET. Under most C environments, this will be defined to be size_t. The second argument is a pointer to a class descriptor or NULL if no class descriptor exists. The third and fourth arguments specify the filename and line number where the FmNew call took place. The return value is a long void pointer to the allocated memory. The FmFree (far memory free) takes one argument. The argument is a memory object that was previously allocated through FmNew(), or NULL. The return value is a long void pointer that is always NULL. The heap manager is discussed in further detail in Chapter 5. For now, this gives us enough information to implement the NEWOBJ() and FREE() macros. 4.5.3 NEWOBJ() and FREE() Implementations Now that the heap manager interface has been specified, the NEWOBJ() and FREE() macros can be designed.
Notice that hObj is the only piece of information needed by NEWOBJ() and FREE(). The size, in bytes, of the object pointed to by hObj is sizeof(*hObj). The address of the class descriptor for hObj is &_CD(hObj). Finally, the filename and line number of the memory allocation are simply __FILE__ and __LINE__. This implementation does in fact work quite well except for two minor problems. The first problem is with __FILE__. Every time it is used, it introduces a new string into the program. However, a solution exists. Use the filename variable that is used by the WinAssert() §3.3 code. The variable is named szSRCFILE. You just have to make sure that USEWINASSERT is placed at the top of the source file. The second problem is with the differences between C and C++. The first pass implementation works just fine in C but not in C++. It involves the usage of void pointers. In C, a void pointer may be legally assigned to a typed pointer. In C++, this is illegal without the appropriate type cast. We do not want to have to pass in the data type of the object, since this would ruin the slick implementation of NEWOBJ() and FREE(). Instead of type casting the right-hand side to the correct data type, why not try to type cast the left-hand side to a void pointer type? How can this be done?
This _LPV() macro effectively changes the type of an l-value object to LPVOID. The danger in this macro is that it assumes the argument is a far pointer to an object. We can now rewrite the NEWOBJ() and FREE() macros as follows.
Regardless of the type of hObj, it is forced into an LPVOID type so that an assignment can be made to hObj without compiler error or warning messages. 4.5.4 Summary The NEWOBJ() and FREE() macros work together to provide an abstraction layer on top of the heap manager code that allows objects to be created and destroyed. 4.6 Fault-Tolerant Methods An important part of the object model presented in this chapter is that it allows us to write code that checks the validity of object handles passed to method functions at run-time. The VERIFY() syntax allows for a block of code to be conditionally executed depending upon the validity of an object handle. This allows a certain degree of fault-tolerance to be built into code. If you are careful in how you design method functions, your program is able to withstand any number of faults, indicating programming errors or bugs, but your program remains running. Without giving consideration to the fact that a method function may fail, a program may end up bombing anyway. So, how should method functions be designed to withstand faults? A model that I use for designing method functions is to treat objects like state machines and methods as state machine transitions. 4.6.1 The State Machine Model A state machine consists of a number of valid states and ways to move from one valid state to another valid state. The important part to remember about this model is that an object instance is always in a valid state. What happens when a method function fails? Consider an object that is in a valid state. We wish to execute a method function on the object. If the handle passed to the method function is valid, the method function executes and takes the object from one valid state to another valid state. If the handle passed to the method function is invalid, the method function does not execute and all objects in the heap stay in their current valid state. What this means is that method functions must never leave the object in an invalid state. The subtle implication of this is that an object must never require more than one method function to be called to take the object from one valid state to another, because if the first method function call succeeds, but the second method function call fails, the object is left in an invalid state. 4.6.2 Designing Method Functions Designing method functions to be fault-tolerant when the method function returns no information is a snap.
Because the method function returns no information, making it fault-tolerant simply means enclosing the body of the method in a VERIFY() block. How do you design a method function to fail gracefully when the method function returns information? At first, this may seem impossible, but in practice I have found it to be an easy task. If the method function fails, setting the return information to a value that is reasonable is OK. If the method function is returning a simple numeric value and zero is a possible value, return zero. If a character buffer is being returned, return a null string or whatever string would be considered valid.
The goal in a failure case is to return information that is reasonable. This way the code calling this method function never knows that the method function failed due to a bad memory pointer, which more than likely would have crashed your program anyway. Consider how to create a fault-tolerant RandNext().
In the case of the RandNext() method function, the failure case is to return zero. While zero is admittedly not random, at least the program using the random number generator is not going to bomb and you will be notified of the run-time object verification failure. 4.6.3 Summary In practice, I have found writing method functions following the state machine model to be a highly effective means of writing a fault-tolerant program. You may be wondering if writing method functions that are fault-tolerant is even worth it. After all, if a method function fails, that means that an object handle is invalid. And if an object handle is invalid, won't the invalid handle just cause an onslaught of failures? During development, yes, an onslaught of failures generally occurs, but what about when the program is in its final shipping form? It has been my experience that most faults in a released program cause only a few failures. Isolating and recovering from these failures using run-time object verification allows the program to continue running. 4.7 Random Number Generator Source Using Classes It is time to bring together everything that has been learned in this chapter and rewrite the random number generator. The interface specification (NEWHANDLE() and function prototypes) remains the same and is contained earlier in this chapter. The final implementation of the random number generator source that uses the macros defined in this chapter is as follows.
The CLASS() macro is used in the source file that implements the HRAND class object, not in an include file. This random number generator implementation is contained in its own source file or module separate from all other modules. This ensures that the HRAND implementation is known only to the functions that implement the random number generator and is not known to functions that simply use random numbers. The interface specification for this random number module is contained in app.h and is accessed through #include "app.h". The interface specification contains the NEWHANDLE(HRAND) declaration and prototypes for RandCreate(), RandDestroy() and RandNext(). USEWINASSERT allows the code to use the WinAssert() macro, which is used by the VERIFY() and VERIFYZ() macros, and makes the current filename known through the szSRCFILE variable, which is used by the NEWOBJ() and WinAssert() macros. The CLASS() macro allocates and initializes a class descriptor for HRAND and binds the HRAND handle to an actual data structure. The class descriptor is used by the NEWOBJ(), VERIFY() and VERIFYZ() macros. The binding of the HRAND handle to an actual data structure allows us to implement the random number generator, because indirections on hRand are now possible. RandCreate() uses NEWOBJ() to create a new object, initializes it and returns the handle to the caller. RandDestroy() performs run-time object verification on the hRand variable by using VERIFYZ(). If hRand is non-zero and valid, the object is freed by using FREE(). Finally, NULL is returned because all destroy methods return NULL by convention. RandNext() performs run-time object verification on the hRand variable by using VERIFY(). If hRand is valid, a new random number is generated. Finally, the next random number (or an error random number of zero) is returned. There is a lot going on behind the scenes in this code. The object-oriented macros are actually hiding a lot of code. It is instructive to see everything that is going on by running this source through the preprocessor pass of the compiler and viewing the resulting output.
4.8 A Comparison with C++ Data Hiding C++ does have a lot to offer (inheritance and virtual functions), but one of the things I do not like about C++ is that it does not allow for the complete data hiding of class declarations. For example, in order to use a class, you must have access to the full declaration of the class. To change the implementation (private part) of a class means that more than likely you have to recompile all source files that just use the object. This gets even more complicated when inheritance is used and a class implementation (private part) is changed because all classes that are derived from the changed class have definitely changed. This will cause a recompile of a lot of code when all you did was change the private part of one class. The bottom line in C++ is that the private parts of classes are not so private! I do not consider the private part of a C++ class to be complete data hiding. The data hiding problem is one of the reasons that the class methodology was developed. The problem with almost every large project is that there is simply too much information in the form of data (class) declarations. This results in a project that is hard to work on because of the information overload. The class methodology allows every data (class) structure to be completely hidden. This is done by moving data declarations out of include files and into the modules that implement the objects. Take, for example, the random number generator just discussed. Users of a random number generator can see only the random number generator interface and nothing more. They see the HRAND data type and the prototypes of the method functions but not the implementation. In fact, the implementation can change totally and only the one source file that implements the random number generator needs to be recompiled. This is because the implementation (class declaration) is declared in only the one source file that implements the object. This is a powerful concept when applied to an entire project. 4.8.1 Another View In §13.2.2 (Abstract Types) of The Design and Evolution of C++, Stroustrup laments that the data hiding view I have expressed above is a common view about C++ but that it is wrong. I disagree. Stroustrup goes on to explain how data hiding can be accomplished in C++ by using abstract classes. The solution involves using two classes: a base class and a derived class. The base class is declared in an include file to be an abstract class. This declares the interface to the object (not the data) which is visible to all users of the object. The derived class is declared in the source file that implements the object. It includes the (private) data and is derived from the abstract base class. This derived class is the real object, which is invisible to all users of the object. However, Stroustrup fails to point out the problems in using abstract types to perform data hiding in C++. Problem one: Creating a new instance. Code that creates an instance of the class must have access to the derived class declaration. Therefore, code that uses the class cannot use the new operator to create a new instance of the class because the code has access to only the abstract base class, not the derived class. One possible solution is to declare a static member function in the abstract base class that is implemented in the derived class module. This function can then create a new derived object, returning a pointer to the base class. Problem two: All method functions must be virtual. All functions that interface to the object must be declared as virtual, which adds function call overhead. Therefore, calling a function declared in the base class is really calling a derived class function. Consider what would happen if the functions were not virtual. They could be implemented, but how would the base class functions access data in the derived class? The problem is that the this pointer in the base class member functions points to the base class, not the derived class. You could type cast from the base class to the derived class, but this is a bad practice and would give you access to only the public section of the derived class, not the private section. The result is that you are forced to use virtual functions for all member functions. Problem three: Two class declarations. Data hiding requires an abstract base class declaration and a derived class declaration that are very similar, but not identical. And all this duplication just because we wanted data hiding. Problem four: Inheritance is disabled. To use inheritance on the class in which data is hidden, you need access to the derived class. But you have access to only the abstract base class declared in an include file, not the derived class declared in the source file that implements the derived class. If you inherit from the abstract base class, you lose the implementation. If you inherit from the derived class, you lose the data hiding. The bottom line is that implementing data hiding in C++ by using abstract classes disables other advanced features of C++ and adds execution overhead. To use data hiding, you give up inheritance. To use inheritance, you give up data hiding. Data hiding through abstract classes and inheritance do not coexist. This is why I disagree with Stroustrup. I feel that using abstract classes to perform data hiding in C++ is an afterthought (abstract classes were not added until C++ version 2.0) and a weak solution to an underlying C++ problem that complete data hiding is not built into the language. However, this underlying problem is also a major strength when it comes to execution speed and standard C structure layout compatibility. In §10.1c of The Annotated C++ Reference Manual, Ellis and Stroustrup hint at a solution (a level of indirection) but dismisses it due to the resulting code being "both larger and slower." Too bad. Those people that want complete data hiding now have to implement it manually. 4.9 Chapter Summary
This book was previously published by Pearson Education, Inc., formerly known as Prentice Hall. ISBN: 0-13-183898-9 |

 4.2.3 Windows Object Model
4.2.3 Windows Object Model