
|
Writing Bug-Free C Code
A Programming Style That Automatically Detects Bugs in C Code
by Jerry Jongerius / January 1995
|
|
|
|
Chapter 2: Know Your Environment
Before you can efficiently institute new programming methodologies
that help eliminate bugs, you need to understand the features
available to you in your programming environment.
Quite often, it is beneficial to ask yourself why a particular
feature is present in the environment. If you are already using the
feature, great, but is there another way you could also be using it?
If you are not using the feature, try to think of why the feature
was added, because someone needed and requested the feature. Why
did they need the feature and how are they using it?
|
Try to become an expert in your environment.
|
In the process of learning about all the features of your
environment, you may eventually become an expert on it. And the
learning process never stops. With each new version of the tools in
your environment, look in the manuals to find out what new features
have been added. Sometimes features are even removed!
2.1 The C Language
 Microsoft C 8.0 (a.k.a. Microsoft Visual C++ 1.0) comes in two
editions: the standard edition and the professional edition. The
standard edition is targeted to the part-time programmer, the
professional edition to the full-time programmer. The professional
edition comes with more manuals and, more important, the Windows 3.1
SDK.
Microsoft C 8.0 (a.k.a. Microsoft Visual C++ 1.0) comes in two
editions: the standard edition and the professional edition. The
standard edition is targeted to the part-time programmer, the
professional edition to the full-time programmer. The professional
edition comes with more manuals and, more important, the Windows 3.1
SDK.
|
No matter which C compiler you are using, it is important that you
fully understand the C programming environment.
2.1.1 The Array Operator
You've used the array operator to index an array before, but have you
given any thought to how the compiler interprets the array operator?
You may not know how it does, especially if you learned C after
learning another language first!
Suppose you have a character array called buffer and an integer
nIndex used to index into the character array. How do you obtain a
character from the character array? Most everyone will tell you
buffer[nIndex], namely, the array name followed by the array index
in brackets.
Did you know that nIndex[buffer] also works! This syntax is not
recommended, but it does work. Do you know why?
The reason that buffer[nIndex] references the same character as
nIndex[buffer] is clearly stated in §A7.3.1 of
The C Programming Language (2nd ed.) as follows:
A postfix expression followed by an expression in square brackets is
a postfix expression denoting a subscripted array reference. One of
the two expressions must have type "pointer to T", where T is some
type, and the other must have integral type; the type of the
subscript expression is T. The expression E1[E2] is identical (by
definition) to *((E1)+(E2)).
The key to understanding array references is to understand "The
expression E1[E2] is identical (by definition) to *((E1)+(E2))." In
terms of the example, buffer[nIndex] is identical to
*((buffer)+(nIndex)). Addition is commutative (i.e., 3 + 4 equals 4
+ 3), which makes *((buffer)+(nIndex)) identical to
*((nIndex)+(buffer)), which is nIndex[buffer].
|
Array reference E1[E2] is identical to *((E1)+(E2)).
|
2.1.2 The Structure Pointer Operator
You all know that if p is a pointer to a structure, that
p->structure-member refers to a particular member of the structure.
Suppose that you could no longer use the structure pointer operator
->. Could you somehow use the other operators in C and continue
coding?
The answer is yes. Instead of p->structure-member, use
(*p).structure-member.
|
If p is a pointer to a structure, the structure reference p->member
is identical to (*p).member.
|
Again, this is not a recommended syntax, but it is good to understand
that it does work and why it works. It is spelled out in §A7.3.3 of
The C Programming Language.
2.1.3 Use the Highest Compiler Warning Level
The warning and error messages of the Microsoft C compiler are
getting better with each release of the compiler. I strongly
recommend that you compile your code at the highest warning level
available to you. For Microsoft C8, this is warning level four.
The command line option for this is /W4.
At warning level four, there may be some warning messages that you
want to totally ignore. An example in Microsoft C8 are warnings
produced by unused declared inline functions. I declare my inline
functions in an include file. The source files then use only those
inline functions that are needed. Unfortunately, the unreferenced
inline functions produce the unreferenced local function has been
removed warning message, which is warning number C4505. To disable
this warning, you can use the warning #pragma in your include files.
Pragma to disable warning number 4505 in Microsoft C8
#pragma warning(disable:4505)
|
Some of the useful, interesting warning messages that you can get
from the Microsoft C8 compiler are as show in Table 2-1.
| Error Number | Error Message |
| C4019 | empty statement at global scope |
| C4100 | unreferenced formal parameter |
| C4101 | unreferenced local variable |
| C4701 | local variable "identifier" may be used without having been
initialized. This warning is given only when compiling with the C8
/Oe global register allocation command-line option. |
| C4702 | unreachable code. This warning is given only when compiling
with one of the C8 global optimization options (/Oe, /Og or /Ol) |
| C4705 | statement has no effect |
| C4706 | assignment within conditional expression |
| C4723 | potential divide by 0 |
Table 2-1: Some interesting Microsoft C8 warning messages.
|
2.1.4 CompilerAssert()
CompilerAssert() is designed to provide error checking at
compile-time for assumptions made by the programmer at design-time.
These assumptions must be documented within comments in the code as
well, but why not also have a compile-time check made whenever
possible?
The reasoning behind this is simple. What if a new programmer is
working on a section of code in which an assumption is made and the
programmer inadvertently changes the code so that the assumption is
now invalid? The bug may not show up for a long time. However, if
the problem could have been flagged at compile-time, it would have
saved a lot of time and effort.
|
Use CompilerAssert() to verify design-time assumptions at
compile-time.
|
The trick in designing CompilerAssert() is to do it in such a way so
that the compiler catches the error at compile-time and yet does not
produce any run-time code.
CompilerAssert() define
#define CompilerAssert(exp) extern char _CompilerAssert[(exp)?1:-1]
|
UPDATE: (exp)?1:-1 used to be (exp)?1:0 but it appears that there are
some UNIX C compilers that do not complain about an array of
zero length even though the standard says the array size must be
greater than zero. So 0 was changed to -1 because every compiler
must complain about an array with negative size.
This CompilerAssert() works because it is really just an array
declaration and the array bound for an array declaration must be a
constant expression that is greater than zero. This is documented
in §A8.6.2 of
The C Programming Language.
Using extern makes sure that no code is generated.
The argument that you pass to CompilerAssert() should be a boolean
expression. This means that it evaluates to zero or one. If it is
one, the CompilerAssert() is valid and so is the array declaration.
If it is zero, the CompilerAssert() is invalid and so is the array
declaration. This will cause the compiler to notify you of an error
and the compilation will stop.
An added bonus is that the argument to CompilerAssert() must be able
to be evaluated at compile-time because the array bound of the array
declaration must be a constant expression. This makes it impossible
for you to misuse CompilerAssert() and have it accidentally generate
some code.
Another bonus is that CompilerAssert() is not limited to use only in
functions or source files. It can even be used in include files as
needed!
It can also be used more than once in the same scope with no
problems. This is due to the usage of extern. Using extern
declares the type of _CompilerAssert; it does not define it.
Declaring the type of a variable name more than once is OK (as long
as the data type is the same). Also, the array size of (exp)?1:-1
changes any non-zero (exp) to one. If this were not done and two
different (exp) values were used by two CompilerAssert()'s, the
compiler would complain.
Some linkers may require that a _CompilerAssert variable exist while
other linkers will optimize out the declared but unused variable.
If the linker that you use requires a _CompilerAssert variable,
place char _CompilerAssert[1]; in any one of your source files to
fix the linker error. The linker that comes with Microsoft C8
does not require this fix.
Let's say that you have coded a function that for some reason
requires an internal buffer to be a power of two. Assuming that an
ISPOWER2() macro already exists, how would you
CompilerAssert() this?
Sample CompilerAssert() usage
...
char buffer[BUFFER_SIZE];
...
CompilerAssert(ISPOWER2(sizeof(buffer)));
...
|
You should test CompilerAssert() to verify that it is working in your
environment. Under Microsoft C8 and UNIX, the following program will
produce a 'negative subscript' error message when compiled.
Testing CompilerAssert(), file test.c
#define CompilerAssert(exp) extern char _CompilerAssert[(exp)?1:-1]
int main(void)
{
/*--- A forced CompilerAssert ---*/
long lVal;
CompilerAssert(sizeof(lVal)==0);
return 0;
} /* main */
Compiling test.c under Microsoft C8, should produce an error C2118
cl test.c
test.c(7) : error C2118: negative subscript
Compiling test.c under UNIX cc, should produce an error message
cc test.c
test.c: In function `main':
test.c:7: size of array `_CompilerAssert' is negative
|
2.1.5 Variable Declarations
Have you ever wondered why you have to declare c is a pointer to a
char as char*c? Do you know if there is a difference between char
buffer[80] and char (*buffer)[80]? At first, C's declaration syntax
may appear difficult, but there is a structure behind it that I am
going to try to explain. I firmly believe that the better you
understand it, the better C programmer you will be.
What is the result of 2 + 3 * 5? It is 17, but why? Why did you
multiply before you added? The answer is that there is a precedence
relationship among the operators. What is the result of (2 + 3) *
5? It is 25 because the parentheses override the natural precedence
relationship. There is a direct analogy to reading C variable
declarations.
You have basically four things to look for: First, parentheses,
(...); second, arrays, [...]; third, functions, (); fourth,
pointers, *. The parentheses, just as in expressions, can override
precedence relationships. Arrays [] and functions () have a higher
precedence than pointers *. Since arrays and functions always
appear to the right of a variable name in a declaration and pointers
always appear to the left of the variable name, this in effect tells
you that you always move right before moving left when reading the
variable declaration.
|
Always try to move right before moving left when reading a variable
declaration.
|
The step-by-step rules for reading most valid variable declarations
are as follows:
- Find the variable name in the declaration. Say "variable name is
a" and try to move to the right.
- To try to move to the right:
- If in an empty set of parentheses, discard the parentheses and try to move to the right.
- If you find a right parentheses, try to move to the left.
- If you find [count], say "array of count" and try to move to the right.
- If you find (args), say "function taking args and returning a" and try to move to the right.
- If you find a semicolon, try to move to the left.
- To try to move to the left:
- If you find an asterisk, say "pointer to a" and try to move to the right.
- If you find a data type, say "data type" and try to move to the right.
Sample variable declaration one
char (*buffer)[80];
^ ^ ^ ^
4 2 1 3
|
1. buffer is a
2. pointer to an
3. array of 80
4. char
In English, the translation goes like this. You start with char
(*buffer)[80] with the caret ^ indicating your position. Find the
variable name buffer and say (1) buffer is a. You now are left with
char (*^)[80]. You move to the right and find a right parenthesis,
so you move to the left, find an asterisk and say (2) pointer to an.
You are now left with char (^)[80]. You move to the right and find
that you are in an empty set of parentheses so you now discard them.
You are now left with char ^[80]. You move to the right and find
an array, so you say (3) array of 80 and try to move to the left.
You are now left with char, a data type, so you say (4) char.
Sample variable declaration two
int (*(*testing)(int))[10];
^ ^ ^ ^ ^ ^
6 4 2 1 3 5
|
1. testing is a
2. pointer to a
3. function taking an integer and returning a
4. pointer to an
5. array of ten
6. integers
Sample variable declaration three: signal function
void (*signal(int, void (*)(int)))(int);
^ ^ ^ ^ ^ ^ ^ ^
8 6 1 2 5 3 4 7
|
1. signal is a
2. function taking an integer for the first argument and a
3. pointer to a
4. function taking an integer and returning a
5. void for the second argument. This signal function returns a
6. pointer to a
7. function taking an integer and returning a
8. void
Going back to the question at the beginning of this section, do you
know if there is a difference between char buffer[80] and char
(*buffer)[80]? What is buffer? Does it look as if buffer is a
pointer to an array of 80 characters in both cases?
In the first case, buffer is an array of 80 characters. In the
second case, buffer is a pointer to an array of 80 characters. It
may help clarify the problem if you ask "What is the data type of
*buffer?" in both cases. In the first case, it is a character. In
the second case, it is an array of 80 characters. So there is a
seemingly slight but quite significant difference.
This is just an introduction to variable declarations. I hope that
you have a new insight into how to read declarations and urge you to
look into the topic further.
2.1.6 Typedef's Made Easy
I can remember when I first started to learn C that I had difficulty
with typedef's. I do not know exactly why, but one day it just hit
me. Take any valid variable definition, add typedef to the front of
it and the variable name is now the data type.
PSTR is a variable that is a character pointer
char *PSTR;
|
PSTR is a new type that is a character pointer
typedef char *PSTR;
|
2.1.7 Name Space
It is possible in C and C++ to spell a typedef name and a variable
name exactly the same. Consider the following.
Code that works, but is a bad programming practice
typedef int x;
int main(void)
{
x x;
return 0;
} /* main */
|
While some people may consider this neat, it leads to programs that
can be hard to read and understand. My advice to you is to assume
that everything has a unique name.
|
Keep all the names in your programs unique.
|
If you follow the programming methodologies described in later
chapters, you will never have the possibility of name collisions.
2.1.8 Code Segment Variables
An interesting feature of the Microsoft C8 compiler is the ability to
place read-only variables in the code segment. Read/Write variables
are not permitted since writing to a code segment is an access
violation, resulting in a general protection fault. A set of macros
that help to place read-only strings in the code segment are as
follows.
CSCHAR define
#define BASEDIN(seg) _based(_segname(#seg))
#define CSCHAR static char BASEDIN(_CODE)
|
CSCHAR (code segment char) may be used just as a char would be used.
Notice the usage of static in the #define. This indicates that the
variable is allocated permanent storage and that it is known only in
the scope in which it is defined.
CSCHAR uses based pointers to place a string in the code segment.
Based pointers are not discussed here since there is an excellent
discussion of based pointers in the Microsoft C documentation and in
the September 1990
Microsoft Systems Journal article
by Richard Shaw.
|
CSCHAR is a great way of placing read-only strings in the code segment.
|
For non-segmented architectures, #define the BASEDIN() macro to be
nothing. While this does not give you a code segment variable, it
does allow you to port the code easily.
Using CSCHAR
CSCHAR szFile[]=__FILE__;
...
OutputName(szFile);
|
Another use of code segment variables is for placing read-only data
tables in the segment in which they are used. One ideal application
of this is in the generation of 16-bit and 32-bit cyclic redundancy
checks (CRCs). There are well known table-driven methods for
speeding up CRC calculations. If these tables were contained in a
data segment, they would use valuable space and would always be in
memory. By embedding the tables in the code segment that does the
CRC calculations, you free up data segment storage. The code
segment is more than likely marked as discardable under Windows;
therefore you now have code and read-only data that is read in from
the disk and discarded as a set.
|
2.1.9 Adjacent String Literals
Consider the following sample code and the output that is produced.
Sample code
#include <stdio.h>
int main(void)
{
printf( "String: %s" "One","Two" "Three" );
return 0;
} /* main */
Output from the sample code
String: TwoThreeOne
|
Notice how adjacent string literals are being concatenated in this
sample code. The first concatenation is between "String: %s" and
"One" to yield "String: %sOne". The second concatenation is between
"Two" and "Three" to yield "TwoThree". So the statement really is
printf( "String: %sOne", "TwoThree" );, which explains the output
produced by this code.
In Microsoft C8, string concatenation is done by the compiler, not by
the preprocessor. This feature is especially useful for splitting
long strings across multiple source lines as in the following
example.
Splitting up long strings
#include <stdio.h>
int main(void)
{
printf( "This is an example of using C's ability to\n"
"contatenate adjacent string literals. It\n"
"is a great way to get ONE printf to display\n"
"a help message.\n" );
return 0;
} /* main */
|
It is also a good way to place macro arguments in a string.
Placing macro arguments in a string literal
#define PRINTD(var) printf( "Variable " #var "=%d\n", var )
|
PRINTD() works by using the
stringizing operator (#)
on the macro
argument, namely #var. This places the macro argument in quotes and
allows the compiler to concatenate the adjacent string literals.
PRINTD() example
#include <stdio.h>
#define PRINTD(var) printf( "Variable " #var "=%d\n", var )
int main(void)
{
int nTest=10;
PRINTD(nTest);
return 0;
} /* main */
PRINTD() example output
Variable nTest=10
|
2.1.10 Variable Number of Arguments
The following discussion is specific to Microsoft C8 and the Intel
machine architecture. Other compilers and machine architectures may
implement function calls and argument passing differently.
C is one of the few languages where passing a variable number of
arguments to a function is incredibly easy and incredibly powerful.
This mechanism is what is used by printf().
Printf() prototype for Microsoft C8 in stdio.h
int __cdecl printf(const char *, ...);
|
The ... declaration indicates to the compiler that the following
types and number of arguments may vary. It can appear only at the
end of an argument list.
Pretend for the moment that you are the compiler writer. How would
you implement a variable number of arguments being passed to a
function?
Traditional architecture. Consider for a moment what happens at the
machine level when a function call is made. A caller pushes onto
the stack the arguments that are required by a function and then the
function call is made, which pushes the return address onto the
stack. You are now executing the function. This function knows
that there is a return address on the stack and the number, type and
relative stack position of each argument. When the function is
ready to return to the caller, it obtains the return address from
the stack, removes the arguments from the stack and returns to the
caller.
Let us now consider printf(). With a variable number of arguments,
how does the printf() function know how many arguments to pop off
the stack when returning from the function? It cannot. The
solution is to let the caller restore any arguments pushed onto the
stack.
Consider the order in which arguments should be pushed onto the
stack. Should the first argument be pushed first or should the last
argument be pushed first?
Printf example
printf( "Testing %s %d", pString, nNum );
|
If the first argument is pushed first (arguments are pushed left to
right), the variable argument section is pushed last. In other
words, the address of the format string is pushed, then a variable
number of arguments is pushed and finally the function call is made,
which pushes the return address. The problem is that the relative
stack location of the format string address changes depending upon
the number of arguments. (See Figure 2-1).
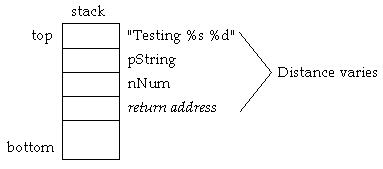
Figure 2-1: Pushing function arguments left to right.
If the last argument is pushed first (arguments are pushed right to
left), the variable argument section is pushed first. In other
words, the variable number of arguments are pushed right to left,
then the address of the format string is pushed and finally the
function call is made, which pushes the return address. The
relative stack location of the format string address is now adjacent
to the return address. (See Figure 2-2).
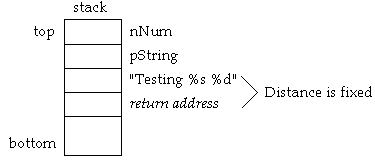
Figure 2-2: Pushing function arguments right to left.
The solution. In order to support passing a variable number of
arguments to functions, it appears that the arguments to a function
must be pushed right to left and that the caller, not the callee, is
responsible for removing the pushed arguments from the stack.
|
2.1.11 Calling Conventions
Were you aware there is more than one way for a function call in
Microsoft C8 to be implemented? Each method has advantages and
disadvantages.
C calling convention. When a function call is made using the C
calling convention, the arguments are pushed onto the stack right to
left and the caller is responsible for removing the pushed
arguments. This convention was designed to allow for a variable
number of arguments to be passed into a function, which can be an
incredibly valuable tool (e.g., the printf() function). The
disadvantage is that the instructions needed to clean up the stack
are performed after every call to the function. If you are making a
lot of calls in your program, this extra code space adds up.
Pascal calling convention. When a function call is made using the
Pascal calling convention, the arguments are pushed onto the stack
left to right and the callee is responsible for removing the pushed
arguments. This convention does not allow for a variable number of
arguments. It does, however, conserve code space since the stack is
cleaned up by the callee and not the caller. Therefore the cleanup
is performed only once. This calling convention is used by all the
Windows API functions, except for DebugOutput() and wsprintf(),
which follow the C calling convention.
Fastcall calling convention. When a function call is made using the
fastcall calling convention, an attempt is made by the compiler to
pass as many arguments as possible through the CPU's registers.
Those arguments that cannot be passed through registers are passed
to the function following the Pascal calling convention. There are
restrictions on when this calling convention can be used. Refer to
the Microsoft C8 reference manual for more information. This
calling convention is used for all functions that are local
(private) to a module (see §6.6.7).
|
2.1.12 Code Generation
It is sometimes incredibly valuable to see the code that the
Microsoft C8 compiler is producing. To do this, use the /Fc command
line option. The resulting .cod file contains the mixed source code
and assembly code produced.
The primary reason to do this is to make sure that the programming
methodologies that you institute are not adding an abnormal amount
of processing-time overhead to the code.
In a few rare circumstances, you can use the code generation option
to track down compiler bugs.
I use this option at times because I am just curious to see how good
the optimizing compiler is. Sometimes I could swear at the compiler
and other times I am amazed at what it is able to do. Microsoft C8
can really do a great job of code optimization. An example that I
like to show is the absolute value macro.
Absolute value macro
#define ABS(x) (((x)>0)?(x):-(x))
|
When the ABS() macro is used on a 16-bit integer, the generated code
without optimizations looks like the following.
Code generated by absolute value macro without optimizations
cmp variable reference,OFFSET 0 ;; is number negative?
jle L1 ;; .yes, handle neg number
mov ax, variable reference ;; no, get number
jmp L2 ;; .and exit
L1: mov ax, variable reference ;; get negative number
neg ax ;; .and make positive
L2:
|
When the ABS() macro is used on a 16-bit integer, the generated code
with optimizations looks like the following.
Code generated by absolute value macro with /Os optimizations
1. mov ax, variable reference ;; get number
2. cwd ;; sign extend
3. xor ax,dx ;; if number is positive, do
4. sub ax,dx ;; .nothing, otherwise negate
|
This optimized assembly code is a work of art. In step 1, the
variable is moved into register ax. Step 2 sign extends ax into dx.
So, if the number is positive, dx gets set to 0; otherwise the
number is negative and dx gets set to all bits turned on (0xFFFF;
negative 1). Provided the number is positive, dx contains 0, so
steps 3 and 4 leave the number unchanged. However, if the number is
negative, dx contains 0xFFFF, so steps 3 and 4 perform a two's
complement, which negates the number. Not bad!
|
2.1.13 Dangling else Problem
Consider the following code.
Code sample showing dangling else problem
if (test1)
if (test2) {
...
}
else {
...
}
|
The problem with this code is that the else does not belong to the
test1 if statement, but instead it belongs to the test2 if
statement. An even bigger problem is that the code may have worked
at some point in the past before a maintenance programmer included
the test2 if statement which previously did not exist. The solution
to the immediate problem is simple, however; add a begin and end
brace to the test1 if statement as follows.
Code sample rewritten to eliminate dangling else problem
if (test1) {
if (test2) {
...
}
}
else {
...
}
|
A programming methodology that I have instituted to completely
eliminate any dangling else problems is to say that every if and
every else must have begin and end braces. No exceptions.
|
Every if block of code and else block of code must have begin and end
braces.
|
2.1.14 Problems with strncpy()
A function in the C library that I never liked much is strncpy(). Do
you know what this function does? Do you know what is going to
happen in the following program?
strncpy() problem, but code may still work
#include <stdio.h>
#include <string.h>
int main(void)
{
char buffer[11];
strncpy( buffer, "hello there", sizeof(buffer) );
printf( "%s", buffer );
return 0;
} /* main */
|
strncpy(string1, string2, n) works by copying n characters of string2
to string1. However, if there is no room in string1 for the null
character at the end of string2, it is not copied into the string1
buffer. In other words, the buffer is not properly null terminated.
If n is greater than the length of string2, string1 is padded with
null characters up to length n.
There are two major problems with strncpy. The first is that string1
may not be properly null terminated. The second is the execution
overhead of null padding.
In the above example, there is no terminating null for the string
copied into buffer. Who knows what the printf() in the example
prints out?
The problem is even worse. Depending upon your computer
architecture, the above example may still work every time! It all
depends upon the alignment of data types. In most cases, 12 bytes
are allocated for buffer instead of 11 due to data alignment
concerns of the underlying CPU. If this extra byte just happens to
be the null character, the code works. If not, the code fails by
printing out more than it should in the printf() statement. It will
just keep on printing characters until it reaches a null character.
|
Replace questionable and confusing library functions. Strncpy() is
an example of a bad function.
|
|
A strncpy() bug existed in the STARTDOC printer escape under Windows
2.x (STARTDOC tells the system that you are starting to print a new
document and it also names the document). If you passed in a string
larger than the internal buffer, which was 32 bytes, the buffer did
not get properly null terminated.
|
2.1.15 Spell Default Correctly
When you code a switch statement, be careful not to misspell default,
because if you do, the compiler will not complain! Your misspelled
version of default is considered by the compiler to be a label.
|
A misspelled default in a switch is considered a label.
|
Remember that a label is any text you choose followed by a colon.
There is no way for the compiler to know that you misspelled default.
2.1.16 Logical Operators Use Short-Circuit Logic
Expressions that are connected by the logical and (&&) and logical or
(||) are evaluated left to right and the evaluation of the
expression stops once the result can be fully determined.
For example, given ((A) && (B)), expression A is evaluated first and
if zero (false), the result of the entire expression is known to be
false so B is not evaluated. B is evaluated if and only if A is
non-zero (true).
Given ((A) || (B)), expression A is evaluated first and if non-zero
(true), the result of the entire expression is known to be true so B
is not evaluated. B is evaluated if and only if A is zero (false).
Exiting out of a logical expression early because the final
expression value is known is called short-circuit logic. Consider
the following example.
Short-circuit logic example
if ((lpMem) && (*lpMem=='A')) {
(code body)
}
|
In this example, lpMem is checked first. If and only if lpMem is
non-null does the second check (*lpMem=='A') take place. This is
important because if both checks took place and lpMem was null, the
*lpMem indirection would more than likely cause a fault and the
operating system would halt the program.
2.1.17 De Morgan's Laws
Do you know how to simplify '!(!a || !b)'? The answer is '(a && b)'.
Being able to simplify a complicated expression can be important
when trying to understand code that someone else has written.
Sometimes being able to not a complicated expression to understand
what the expression is not helps you understand the expression.
De Morgans laws
1. !(a && b) == (!a || !b)
2. !(a || b) == (!a && !b)
|
One simple rule applies to De Morgans Laws. To not a logical
expression, not both terms and change the logical operator. This
helps greatly when you have a complicated logical expression where
one of the terms is another logical expression. To not a term that
is itself a logical expression, simply reapply the rule.
|
To not a logical expression, not both terms and change the logical
operator. Apply this rule recursively as needed.
|
2.2 C Preprocessor
2.2.1 Writing Macros
How do you write macros? Are you aware of the problems that macros
can have? Let's take the following SQUARE() macro.
SQUARE() macro, has problems
#define SQUARE(x) x*x
|
What is SQUARE(7)? It is 49. What is SQUARE(2+3)? Is it 25? No,
it is 11. Expanding the macro gives 2+3*2+3. The multiplication is
done first, so now you can see why the result is 11. You may now be
inclined to rewrite the SQUARE() macro as follows.
SQUARE() macro, has problems
#define SQUARE(x) (x)*(x)
|
This macro may still have problems with the unary operators.
Consider sizeof SQUARE(10), which is really sizeof (10)*(10), which
is not sizeof((10)*(10))! The correct way to write SQUARE() is as
follows.
SQUARE() macro, final form
#define SQUARE(x) ((x)*(x))
|
Notice the extra set of parentheses. This too has problems in some
special circumstances. Namely, how does SQUARE(++x) behave? It is
actually undefined because it is up to the compiler vendor to decide
exactly when multiple post- / pre- increment/decrement operations
take place in relation to each other in the entire statement. Let's
say x contains three; what is ((++x)*(++x))? Is it 16, 20 or 25?
Or what about SQUARE(x++), which is ((x++)*(x++)). Is it 9? Is it
12? The answer is compiler specific.
|
Macros that reference an argument more than once have problems with
arguments that have side effects.
|
A possible solution to the problem of side effects is to use inline
functions, a feature of C++. This is OK, but in doing so, you lose
the polymorphic behavior of working on multiple data types
automatically. This is because inline functions are true functions
and you must declare the data types of the arguments. So, you must
write a new inline function for every data type that you want the
inline function to work with. This admittedly is a little bit of a
pain, but it may be worth it in some cases.
The best solution, available only in some C++ environments, is the
use of templates. Templates are used to describe how to do
something, while not specifying the data type to use. Templates are
still new and not included in all C++ development environments.
They are not included in Microsoft C8.
2.2.2 Using Macros That Contain Scope
Have you ever written a macro that needed its own scope? If so, how
did you go about writing it? Consider the following example.
A macro that needs a scope, has problems
#define POW3(x,y) int i; for(i=0; i<y; ++i) {x*=3;}
|
The problem with this macro is that because it uses temporary
variable i, the body of the macro must be contained within its own
scope in C and should be contained in its own scope in C++.
Consider the following.
A macro with scope, has problems
#define POW3(x,y) {int i; for(i=0; i<y; ++i) {x*=3;}}
|
Even this latest fix may have problems as this next example shows.
Using POW3(), has problems
if (expression)
POW3(lNum, nPow);
else
(statement)
|
The problem is the semicolon after POW3. The POW3 macro without the
semicolon is a valid statement by itself due to the begin/end braces
creating a scope. Adding the semicolon only creates a new
statement, which is the problem since the else can then no longer be
paired with the if.
So how can a macro, no matter how many statements it contains, be
enclosed in its own scope, be treated like one statement and require
that it be terminated by a semicolon? The solution to this problem
is subtle but very elegant.
A macro with scope, final form
#define POW3(x,y) do {int i; for(i=0; i<y; ++i) {x*=3;}} while(0)
|
By using a do/while loop that never loops, the macro body gets its
own scope and requires a semicolon after it. Most optimizing
compilers will optimize away the loop that never loops.
|
Using a do/while loop that never loops is a great way to hide the
body of a macro within its own scope.
|
However, some C compilers (Microsoft C8 included) may complain about
the constant zero in while(0) when the highest warning level of the
compiler is used. If this occurs, you can use a #pragma to disable
the warning.
Pragma to disable warning number 4127 in Microsoft C8
#pragma warning(disable:4127)
|
2.2.3 If Statements in Macros
If you write a macro that contains if statements, you must be careful
not to have the
dangling else §2.1.13
problem previously discussed.
Macro containing if/else, has problems
#define ODS(s) if (bDebugging) OutputDebugString(#s)
|
One solution would be to enclose the body of the macro in a do/while
loop that never loops, which would have the added benefit of
requiring the macro to be terminated with a semicolon. This version
of ODS() has the dangling else problem. However, through careful
usage of the if/else statement, you can eliminate the problem.
Macro containing if/else, problem solved
#define ODS(s) if (!bDebugging) {} else OutputDebugString(#s)
|
This version of ODS() no longer has the dangling else problem. The
solution is to always rework the macro so that it contains both an
if clause and an else clause. Again, a semicolon is required after
a macro that uses this new form.
Be careful when writing macros that contain if/else statements not to
end the macro with an ending brace, or the macro terminated by a
semicolon will actually be treated like two statements.
|
Never conclude a macro with an ending brace.
|
2.2.4 Ending a Macro with a Semicolon or a Block of Code
It is possible to use the subtleties of an if/else statement in a
macro to your advantage. For example, how would you write a macro
that must either be terminated with a semicolon or a block of code?
The WinAssert() §3.3
macro uses this technique to allow a block
of code to be conditionally executed.
WinAssert() syntax
/*--- Ended with a semicolon ---*/
WinAssert(expression);
/*--- Or ended with a block of code ---*/
WinAssert(expression) {
(block of code)
}
|
Notice that the WinAssert() syntax allows either a semicolon or a
block of code to follow it. The WinAssert() macro looks like the
following.
WinAssert() macro
#define WinAssert(exp) if (!(exp)) {AssertError;} else
|
The key to this WinAssert() macro is that whatever follows the macro
is what follows the else statement. A semicolon or a block of code
are both valid in this context.
2.2.5 LOOP(), LLOOP() and ENDLOOP Macros
The vast majority of the loops that I have written start at zero,
have a less than comparison with some upper limit and increment the
looping variable by one every iteration. Since this is the case,
why not abstract this out of the code into a macro? In addition,
since the looping variable is used to control the loop, it should
not be visible (accessible) outside the loop. The solution involves
three macros. The first two, LOOP() and LLOOP(), set up the for
loop for int's and long's. The third macro, ENDLOOP, finishes what
LOOP() and LLOOP() started.
The LOOP(), LLOOP() and ENDLOOP macros
#define LOOP(nArg) { int _nMax=nArg; int loop; \
for (loop=0; loop<_nMax; ++loop)
#define LLOOP(lArg) { long _lMax=lArg; long lLoop; \
for (lLoop=0; lLoop<_lMax; ++lLoop)
#define ENDLOOP }
|
Notice how the extra begin/end brace pair limit the scope of the loop
and lLoop variables and that the loop limit is evaluated only once.
This allows costly expressions such as strlen(). to be used as the
loop limit because the evaluation takes place once, not on every
loop iteration.
Sample code that uses LOOP(), LLOOP() and ENDLOOP
LOOP(10) {
printf( "%d\n", loop );
} ENDLOOP
LLOOP(10) {
printf( "%ld\n", lLoop );
} ENDLOOP
|
You may be wondering why the C++ method of declaring the loop
variable inside the for statement isn't used instead. This would
allow you to get rid of the begin brace and ENDLOOP macro.
C++ loop code, with variable declaration problems
for (int loop=0; loop<10; ++loop) {
...
}
...
for (int loop=0; loop<10; ++loop) {
...
}
|
Unfortunately, the C++ method defines the loop variable from the
definition point until the end of the current scope (but this is
changing in C++). In other words, the loop variable would now be
known outside the scope of the loop and using two LOOP()'s in the
same scope would end up declaring the looping variable twice, which
cannot be done in the same scope.
2.2.6 NUMSTATICELS() Macro
Provided you have an array in which the number of elements in the
array is known to the compiler, write a macro NUMSTATICELS() (number
of static elements) that given only the array name returns the
number of elements in the array. Consider the following example.
NUMSTATICELS() desired behavior example
#include <stdio.h>
#define NUMSTATICELS(pArray) (determine pArray array size)
int main(void)
{
long alNums[100];
printf( "array size=%d\n", NUMSTATICELS(alNums) );
return 0;
} /* main */
Desired output
array size=100
|
How would you write NUMSTATICELS() so that the above example works?
The solution is to write NUMSTATICELS() as follows.
NUMSTATICELS() macro
#define NUMSTATICELS(pArray) (sizeof(pArray)/sizeof(*pArray))
|
This macro works because sizeof(pArray) is the size in bytes of the
entire array and sizeof(*pArray) is the size in bytes of one element
in the array. Dividing gives the maximum number of elements
possible in the array. NUMSTATICELS() does not need to work on a
pointer to a dynamically allocated array.
So, in the above example, if we assume that sizeof(long) is 4,
sizeof(alNums) is 400 and sizeof(*alNums) is 4. Dividing gives the
desired output of 100.
2.2.7 Preprocessor Operators
Ask any C programmer what the preprocessor is used for and you hear
things like macros, including header files, conditional compilation,
and so on. These are obvious and useful features. However, ask the
same C programmer what preprocessor operators are and you may get a
blank stare.
The two most useful preprocessor operators are the stringizing
operator (#) and the token pasting operator (##). Both of these
operators are usually used in the context of a #define directive.
The token pasting operator is at the heart of the class methodology
introduced in Chapter 4.
Stringizing operator (#). This operator causes a macro argument to
be enclosed in double quotation marks. The proper syntax is
#operand.
Stringizing operator example
#define STRING(x) #x
|
Therefore, STRING(hello) yields "hello".
In some older preprocessors, you accomplish stringizing of x in a
macro (i.e., #x) directly by enclosing the macro argument x in
quotes (i.e., "x"). Try this technique if you do not have a
standard C compiler that allows stringizing.
Token pasting operator (##). This operator takes two tokens, one on
each side of the ## and merges them into one token. The proper
syntax is token1##token2. This is useful when one or both tokens
are expanded macro arguments. Consider the following example.
Token pasting operator example
CSCHAR szPE7008[]="function ptr";
CSCHAR szPE700A[]="string ptr";
CSCHAR szPE7060[]="coords";
...
#define EV(n) {0x##n,szPE##n}
static struct {
WORD wError;
LPSTR lpError;
} BASEDCS ErrorToTextMap[]={ EV(7008), EV(700A), EV(7060) };
|
In this example, EV(7008) expands to {0x7008,szPE7008}, which
initializes the wError and lpError elements of ErrorToTextMap (which
happens to be in the code segment). For me, the EV() macro makes
this code shorter and easier to understand.
2.2.8 Token Pasting in a Reiser Preprocessor
In some old preprocessors that do not support the token pasting
operator, it is still possible to perform token pasting provided the
preprocessor follows the Reiser model. This is done by replacing ##
with /**/. This works because the comment /**/ is removed and
replaced with nothing, effectively pasting the tokens on either side
of /**/.
This technique does not work in newer standard C compilers that
replace comments with a single space character. However, newer
standard C compilers have the token pasting operator, so this
technique is not needed.
2.2.9 Preprocessor Commands Containing Preprocessor Commands
Have you ever wanted to write a macro that referred to another
preprocessing directive? Consider the following example.
Optimize On/Off macros, which do not work
#define OPTIMIZEOFF #pragma optimize("",off)
#define OPTIMIZEON #pragma optimize("",on)
|
The OPTIMIZEOFF and OPTIMIZEON macros attempt to abstract out how
optimizations are turned off and turned on during a compilation.
The problem with these macros is that they are trying to perform
another preprocessor directive, which is impossible with any
standard C preprocessor. However, this does not mean that it cannot
be done.
The solution to this problem is to run the source through the
preprocessor twice during the compile instead of just once. Most
compilers allow you to run only the preprocessing pass of their
compiler and redirect the output to a file. If this output file is
then run back through the compiler, the optimize macros work!
Testing extra preprocessor pass in Microsoft C8 for C code
cl -P test.c
cl -Tctest.i
Testing extra preprocessor pass in Microsoft C8 for C++ code
cl -P test.cpp
cl -Tptest.i
|
2.3 Programming Puzzles
This section is designed to get you thinking. Some of the puzzles
presented here have real programming value, while others have no
programming value whatsoever. The point of these exercises is to
get you thinking in a new light about things you already know about.
If you want to skip this section, go to §2.4
2.3.1 ISPOWER2() Macro
Try to spend some time coming up with a macro that returns one if the
macro argument is a power of two, or returns zero if the macro
argument is not a power of two. The solution is as follows.
Macro that determines if a number is a power of two
#define ISPOWER2(x) (!((x)&((x)-1)))
|
This ISPOWER2() macro works for any number greater than zero because
any number that is a power of two has the binary form "100...0",
namely, a binary one followed by any number of binary zeros.
Subtracting one from this number changes the leading binary one to
zero and all trailing binary zeros to binary ones. Therefore,
ANDing with the original number produces zero. Any number that is
not a power of two has at least one bit in common with that number
minus one. Therefore ANDing produces a non-zero number. Since this
is just the opposite of the desired return value, the value is NOTed
to get the desired result.
For example, the number 16 in binary is 00010000. Subtracting 1 from
16 is 15, which in binary is 00001111. So, ANDing 00010000 (16)
with 00001111 (15) yields 00000000 (0) and NOTing gives 1. This
tells us the number 16 is a power of two.
As another example, the number 100 in binary is 01100100.
Subtracting 1 from 100 is 99, which in binary is 01100011. So,
ANDing 01100100 (100) with 01100011 (99) yields 01100000 (96) and
NOTing gives zero. This tells us that the number 100 is not a power
of two.
2.3.2 Integer Math May be Faster
Let us say you have an integer x and an integer y and you want x to
contain 45 percent of the value contained in y. One obvious
solution is to use x = (int)(0.45*y);. While this works, there is a
shortcut that avoids floating pointer math and uses only integer
arithmetic. 0.45 is just 45/100 or 9/20. So why not instead use x
= (int)(9L*y/20);? The only disadvantage of this technique is that
you need to watch out for overflows. Play around with this
technique with some small numbers by hand until you get a good feel
for what is going on.
2.3.3 Swap Two Variables without a Third Variable
This is an old assembly language trick that can also be used in C.
Given two assembly language registers, how can you swap the contents
of the registers without using a third register or memory location
(and, of course, not using a swap instruction if the assembly you
are familiar with has such an instruction). The solution is as
follows.
Swapping integers x, y without a third integer using C
1. x ^= y;
2. y ^= x;
3. x ^= y;
|
After step 1, x contains (x^y). After step 2, y contains (y^(x^y)),
which is just x. Finally, after step 3, x contains ((x^y)^x), which
is y. This is it!
The trick to this technique is realizing that any number XORed with
itself is 0. XOR also has useful applications in GUI environments.
2.3.4 Smoother XORs in a Graphical User Interface
A standard technique used in Graphical User Interfaces is to invert
part of the display screen (using XOR) while the user is resizing a
window to show the user the new size of the window. XORing again to
the same screen locations restores the screen image to its original
form.
So, when the user starts to resize the window, the location is marked
by XORing the window border. When the user moves a little bit, the
same location is XORed to remove the highlight, the proposed border
is sized to the new location and it is XORed onto the screen,
showing its new location. This process works pretty well but it
results in screen flicker. The entire inverted window border is
constantly being placed down and removed in its entirety.
Let's analyze the process in abstract terms using regions. We have
three components: the screen (SCRN), the old border region (OBR)
and the new border region (NBR). The border is placed down by a
SCRN ^= OBR operation. As the user moves the mouse, the goal is to
turn the screen containing the old border region into a screen
containing the new border region. (See Figure 2-3).
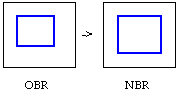
Figure 2-3: Moving a window border
The old way of implementing this is to remove the old border followed
by placing down the new border. The old border is removed by a SCRN
^= OBR operation and the new border is placed down by a SCRN ^= NBR
operation. In other words, SCRN = (SCRN ^ OBR) ^ NBR. (See Figure
2-4)
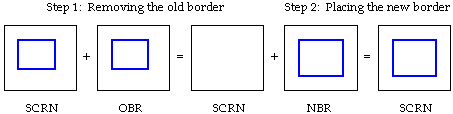
Figure 2-4: The standard way of moving a window border.
Does it really matter in what order you XOR? No, not at all, since
XOR is associative. So why not instead do SCRN = SCRN ^ (OBR^NBR)?
The screen now updates without even a hint of flicker! This is
because you are finding the difference between the old border region
and the new border region (i.e., XOR) and XORing that difference
onto the screen. The result is that the old border is erased and
that the new border is now visible. (See Figure 2-5).
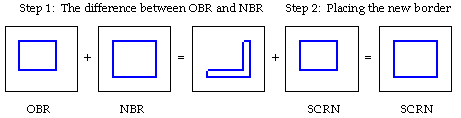
Figure 2-5: A better way to move a window border
The key to this magic is having region support provided to you by the
environment you are working on.
|
For Microsoft Windows, the functions of interest are CreateRectRgn(),
SetRectRgn() and CombineRgn().
|
2.3.5 Is ~0 More Portable Than 0xFFFF
How do you fill an integer variable so that all bits are turned on,
but in a portable, data type size independent manner? Do you use
-1? No, because this assumes a two's complement machine. What if
you are on a one's complement machine? Do you use 0xFFFF,
0xFFFFFFFF or whatever? No, since this assumes that there are a
particular number of bits in an integer.
The only thing you can be sure of in every machine is that zero is
represented as all bits turned off. This is the key. There is a
built-in C operator to flip all the bits and it is the one's
complement ~ operator. Therefore, ~0 fills an integer value with
all ones in a portable manner.
This technique also works well to strip off the lower bits of a
number in a portable manner. For example, ~7 has all the bits in
the resulting number turned on except for the lower three bits.
Therefore, wSize&~7 forces the lower three bits of wSize to zero.
2.3.6 Does y = -x; Always Work?
You may be wondering if I wrote that statement correctly. I did. Do
you know when y = -x fails? It fails on a two's complement machine
when x equals the smallest negative number. Consider a 16-bit two's
complement number where the smallest negative number is -32768. So,
if it fails, what is the result of negative -32768? It is -32768.
The valid range of numbers on a two's complement machine for a short
integer is -32768 to 32767. There is one more negative number than
there are positive numbers.
2.3.7 One's and Two's Complement Numbers
In one's complement notation, the negative of a number is obtained by
inverting all the bits in the number. For short (16-bit) integers,
this results in a range from -32767 to 32767. So what happened to
the extra number? Well, there are now two representations for zero.
Namely a negative zero (all bits on) and a positive zero (all bits
off). One's complement works, but it requires special case hardware
to make sure everything works. One day someone came up with the
bright idea of two's complement, which is simply one's complement
plus one. It eliminates the two representations for zero and
eliminates the special case hardware.
Two's complement negation as a macro
#define NEGATE(x) (((x)^~0)+1)
|
So why can two's complement be implemented so efficiently? For
simplicity, let's assume a three-bit unsigned integer. The integer
can take on the values from 0 to 7. Any arithmetic on the numbers
are modulo 8 (remainder upon division by 8). As an example, adding
1 to 7 is 0 and adding 3 to 7 is 2. You can verify this by going to
the first number (e.g., 7) on the base eight number line and moving
right the number of times specified by the second number (e.g., 3).
Base eight number line
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 ...
|
You will quickly realize that adding 7 to any number is like
subtracting 1, adding 6 is like subtracting 2, and so on. So what
if you simply label 4 through 7 slightly differently.
Base eight number line as signed numbers
0 1 2 3 -4 -3 -2 -1 0 1 2 3 -4 -3 -2 -1 ...
|
Half the numbers are now negative and the other half are for zero and
positive numbers. So adding negative 1 (i.e., 7) to any number
really does work. That is it! This two's complement technique can
be extended to any bit size.
2.4 Microsoft Windows
One of the first things one learns about the Windows environment is
that it allows for true code sharing. An example of this is running
an application, such as Notepad, more than once. A new data segment
is created for each new instance of the application, code segments
and resources being shared between the two instances. This is why
there are such things as "handle to a module" and "handle to an
instance." The module handle basically refers to the executable
file, the common part per instance, and the instance handle refers
to the application data segment, the unique part per instance.
2.4.1 Dynamic Link Libraries (DLLs)
A more powerful mechanism of sharing both code and data is provided
through the use of Dynamic Link Libraries or DLLs. In fact, most of
the Windows environment is a set of DLLs, namely the USER, KERNEL
and GDI DLLs. For DLLs, no matter how many applications use or
reference them, only one set of code is loaded and only one data
segment is loaded (when using the preferred medium memory model).
Writing DLLs allows you to write code that is truly sharable among
applications and promotes the "write-it-once" attitude. After all
you have done to learn Windows, why not write the majority of your
code as a DLL so that you now have a library of code waiting to be
used by your next killer application. You may argue that there is
no need for this since all you have to do is copy the code, but what
you have gained is code maintainability. Let's say you rewrite some
of the shared code. With a DLL you change it once. With multiple
copies of the code you have to change it multiple times.
2.4.2 Special DLL DS!=SS Concerns
DLL programming is one of the least understood concepts of Windows
programming because it is considered "Advanced Programming" and is
always one of the last chapters of any Windows book. DLL
programming is also more difficult than programming for an
application due to "DS!=SS" (data segment does not equal stack
segment) concerns.
In a medium model Windows program you typically have multiple code
segments and one data segment. The stack for the application is
contained within the application data segment so that near pointers
can access both data segment data and stack segment data. It then
makes sense to set DS==SS (data segment equals stack segment). When
a DLL is called, the data segment is changed but not the stack
segment. You now have a "DS!=SS" situation. This allows the DLL
function to access parameters passed to the function (on the stack)
and private data (in the DLL data segment). However, a near pointer
can access only the data segment in a DLL, not the stack segment.
This causes problems for a fair number of useful C library
functions. From experience I would stay away from C library calls
in a DLL unless you have a good reason to use them. Instead, code
the functionality yourself.
2.4.3 Real-Mode Windows
Windows 1.x and 2.x were real-mode operating systems. They did not
use the protected-mode architecture of the Intel CPU. This all
changed with the introduction of Windows 3.0. It supports
real-mode, standard-mode (a.k.a. 286 mode) and enhanced-mode (a.k.a.
386 mode). With the introduction of Windows 3.1, real-mode support
has been removed.
Have you ever wondered how Windows running in protected-mode could
continue to run old Windows applications that were designed for
real-mode? That this even works is a tribute to the original
designers of Windows 1.0! The question should be rephrased as
follows: Can you believe that Microsoft got a protected-mode
architecture to run under the real-mode of the CPU?
I want to give you an inside look into one of the more interesting
features of Windows and how it was implemented under real-mode. The
feature is discardable code segments.
An application under Windows 2.x is usually composed of many code
segments. Most of the code segments were movable and discardable.
In other words, the code could be moved around in memory by the
operating system as needed and if memory became tight, the code
segment could be discarded from memory to make room for other things.
As an example, let's say you have function A in segment A that calls
function B in segment B. There is now a far return address on the
stack. Now let's assume that segment A is discarded. Under a
protected-mode operating system, returning to function A would fault
to the operating system and segment A would simply be loaded back
into memory. What about real-mode? Returning to function A cannot
cause a CPU fault.
How would you solve this problem?
The solution is rather ingenious and requires compiler support to be
fully implemented. Suppose that a segment is moved in real-mode
memory. Since the segment address has changed, walk the stack and
patch those return addresses on the stack that have the old segment
address with the new segment address. If the segment is discarded,
walk the stack and patch the address with an address into the
operating system that reloads the segment.
Walking the stack under the Intel segmented architecture is
complicated by the fact that the addresses can either be near (16
bit) or far (32 bit). So when walking the stack the operating
system has no way of knowing if it should expect a near or far
address. It cares only about the far addresses because near
addresses do not have to be patched.
The solution has to do with the stack frame that is built for all
functions and the fact that the Intel stack segment is word aligned.
Within each stack frame is a pointer to the previous stack frame.
Since this pointer is word aligned, the lower bit is always zero.
If you were to use this bit as a near/far indicator, you could then
walk the stack with no problems. The compiler generates the code
that correctly sets this bit to indicate the near or far nature of
the function.
This technique was used by real-mode Windows compilers but is now no
longer used since Windows is a protected-mode only operating system.
2.4.4 Why MakeProcInstance() Was a Design Flaw
After seeing how good a job Microsoft did with designing Windows to
work under real- and protected-mode you may be amazed to learn how
another problem was solved.
When an application such as Notepad is run multiple times, only one
set of code ever gets loaded because code is shared under the
Windows operating system. However, each Notepad does get its own
copy of its data segments. Because Windows is event driven, there
are many occasions where Windows calls your code. When it calls
your code, how does Windows bind to the correct data segment?
The solution the Windows designers came up with is that instead of
providing the address of the callback directly to Windows, you
instead pass the address of some thunk code that binds to the
correct data segment and then calls the true callback. This thunk
code is created using MakeProcInstance().
A thunk is usually just a small piece of code that gets executed just
before a real function gets executed. The purpose of a thunk is
usually to bind something to the function. In the case of
MakeProcInstance(), this something is the correct data segment.
MakeProcInstance() prototype
FARPROC MakeProcInstance( FARPROC lpProc, HINSTANCE hInst );
|
However, as it turns out, the correct data segment value used by the
thunk code is already in the SS (stack segment) CPU register because
an application's stack is contained in its data segment (i.e.,
DS==SS). This eliminates the need for the thunking code and hence
MakeProcInstance() because the correct data segment to use is always
in the SS register.
All compilers for the Windows environment now have compiler switches
that bind to the correct data segment from the value in the SS
register. MakeProcInstance() never needs to be used again. Under
Microsoft C8, the command line options for this is /GA (for
applications).
This technique of eliminating the need for MakeProcInstance() was
originally developed by the brilliant Windows programmer Michael
Geary and distributed in his FixDS utility. For an interesting
discussion about Geary and the Adobe Type Manager, refer to "The
Geary Incident" in Undocumented Windows.
2.4.5 Optimizing the Compiler Options
The Microsoft C8 compiler assumes the worst when selecting default
command line options. The compiler defaults to options that will
work in all environments. However, the default options are not
always the best options and not optimizing them will add execution
overhead to your program.
Instruction sets. For example, since Windows now requires at least a
286 processor (i.e., protected-mode), you can use the /G2 command
line option, which tells the compiler to generate instruction
sequences using the 286 instruction set. If you know that your
program will be run only on 386's or better, you can even use the
/G3 option, which tells the compiler to generate code using the 386
instruction set.
Prolog/Epilog code generation. Due to historical reasons in Windows
using the real-mode architecture of the Intel processor, far
functions required special treatment by the compiler. However, if
your application is a protected-mode Windows application (and every
one is today), you can optimize how the compiler generates code for
these far functions. For applications, use the /GA command line
option and explicitly place the __export keyword on any callback
functions. For DLLs, use the /GD command line option and explicitly
place the __export keyword on any callback or API functions.
Pascal calling convention. To reduce the amount of code generated to
support function argument passing, it is recommended that you use
the Pascal calling convention. The /Gc command line option tells
the compiler that all functions should default to the Pascal
calling convention. See the
Pascal calling convention §2.1.11
and how it compares to the default
C calling convention §2.1.11.
Remove stack-check calls. It is recommended that you compile your
Windows program with stack probe checks turned off. This is done
through the /Gs command line option.
2.4.6 Dynamic Dynamic Linking
Dynamic linking is at the core of the Windows operating system. It
is a mechanism for resolving references to operating system
components at load-time. For example, if your program calls the
Windows PolyLine() function, your program does not contain the
PolyLine() code. Instead, it contains a call to code that does not
exist in your program. When the program is loaded into memory, the
operating system patches your code so that it calls the PolyLine()
code contained in the operating system. This is dynamic linking.
Dynamic dynamic linking allows you, the programmer, to link to a
function at run-time. This is done through the Windows
LoadLibrary(), GetProcAddress() and FreeLibrary() functions.
One good reason for using dynamic dynamic linking is that it allows a
program to optionally use advanced features of the operating system
while still allowing the program to be run on minimally configured
systems. Suppose you write a simple terminal emulator that uses
either an asynchronous port or a network port. By linking to the
network library, your program cannot be run on machines that have
only an asynchronous port and not a network connection because the
program requires the network library to be present in order to be
run. However, by using dynamic dynamic linking to the network
library, your program can attempt to bind to the network library
only if the user has selected an option that requires the network
library to be present.
2.4.7 Messages
Windows is a message-based system. Each application running in the
system has a message queue from which it is responsible for removing
and dispatching messages.
It is important to realize that not all Windows messages are alike.
Some messages are telling your program that an event has already
happened (notification messages). Other messages are requesting
your program to perform some action (action messages). This
distinction is subtle and yet important to understand because
knowing the difference will allow you to code simple solutions to
what seem to be complex problems.
Notification messages. Receiving the WM_MOUSEMOVE message is an
example of a notification message. Whenever the mouse is moved on
the screen, some window will receive this message. Ignoring this
message has no effect. The mouse pointer will continue to move on
the screen.
Action messages. Receiving the WM_COMMAND message is an example of
an action message. It is usually sent to your program in response
to the user's selecting a menu item. Ignoring this message would be
serious because your program is supposed to perform an action based
upon this message.
Suppose you have a dialog box that contains several edit controls.
The tendency of users of this dialog box is to type text into the
first edit control and then press the enter key to advance to the
next edit control. The problem with pressing the enter key is that
it is the same as pressing the OK button, which exits the dialog
box! So how can you allow the enter key to be pressed to advance to
the next edit control?
The first inclination of a lot of programmers is to attempt to use
subclassing to solve this problem. However, there is a much simpler
solution. Pressing the enter key results in the dialog box manager
sending an IDOK WM_COMMAND message to the dialog box. This message
is an action message, not a notification message. The solution is
to check in the IDOK processing code if the focus is on the OK
button. If so, the dialog may be exited; otherwise advance the
focus to the next edit control (and do not exit the dialog).
|
Trapping action messages is easier than subclassing is some cases.
|
Another good example involves moving windows. When the user moves
the mouse over the caption area of a window and drags, the window is
moved by Windows. Suppose you want this same moving behavior when
the user clicks and drags in the window. At first glance it would
appear that you would have to write a lot of code. The solution
involves realizing how the WM_NCHITTEST action message works. This
message is sent by the Windows internals asking the window to
perform hit testing. Windows wants to know what part of the window
(caption bar, left border, right border, client area, etc.) a
certain point is in. The following code is the solution to the
problem.
Changing a window's client area to behave like the caption area
case WM_NCHITTEST: {
LRESULT lRet=DefWindowProc(hWnd, message, wParam, lParam);
return ((lRet==HTCLIENT)?HTCAPTION:lRet);
break;
}
|
Placing this code in the window procedure of the appropriate window
solves the problem. Since WM_NCHITTEST is an action message, we
first call the default window procedure, DefWindowProc(), to perform
the standard hit testing. Next we return the result of the hit
test, but change the client area (HTCLIENT) to look like the caption
area (HTCAPTION).
|
2.5 Chapter Summary
- Before you can efficiently institute new programming methodologies
that help reduce bugs in your programs, you need to fully understand
your programming environment. Try to become an expert in your
environment.
- Study your environment and learn as much about it as you can. The
learning process never stops. Even if you have been programming in
C for many years, you will still learn new nuances about C all the
time.
- Your goal should be to become an expert in your programming
environment. While becoming an expert is not a prerequisite to
developing programming methodologies, it does help you develop more
advanced methodologies.
Copyright © 1993-1995, 2002-2026 Jerry Jongerius
This book was previously published by Pearson Education, Inc.,
formerly known as Prentice Hall. ISBN: 0-13-183898-9
|