The Dark Problem with AQM in the Internet
August 23, 2014 (updated 09/03/2014) - Technology Blog Index
duckware.com/darkaqm
|
1. The problem with AQM in the Internet
|
|
AQM (Active Queue Management) algorithms,
like CoDel, RED, PIE, and many other variants,
are a way of dealing with Flow Fairness and
Bufferbloat.
However, with AQM comes a dark consequence:
When an device intentionally drops a successfully received packet, even
network experts can't pinpoint the responsible device.
Before AQM, ping, traceroute, or numerous other tools, could be used to
discover where queueing was likely taking place -- the most likely location for
a packet drop.
But after AQM, actual queueing is masked -- meaning that a network with significant
queueing issues can still show 'normal' ping times.
So after AQM, finding what device actually dropped a packet is virtually impossible,
unless you have access of all devices in a network path. And
that will never happen over an Internet connection -- where (1) you connect to (2) an ISP,
which connects to (3) a peer, likely connecting to (4) other peers, and then finally
to (4) a destination.
AQM is great from an end-user perspective -- much better responsiveness (latency), even on congested networks.
But AQM is bad from a diagnostics perspective -- finding out which device intentionally
dropped a packet for a particular TCP connection, even for network experts, is impossible.
|
2. AQM hides detecting real queueing in the network
|
|
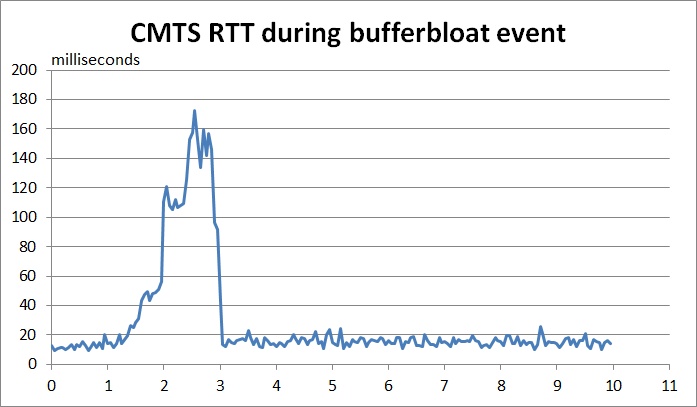
As a prime example, I used to be able to ping my CMTS (Cable Modem Termination System)
in Florida to measure the amount of queueing within the CMTS to
my cable modem -- as the ping reply millisecond times would 'indicate' the egress
queue size within the CMTS to my modem (see example chart right).
In GA, I could easily induce (and measure) over 2000ms of bufferbloat within a Comcast CMTS.
But after AQM, ping times to my CTMS in FL are now always 'normal', regardless of
any other activity -- even during a large file download known to cause significant
queueing, and itself drop packets.
After AQM, even with bufferbloat, CTMS RTT graphs are flat.
Under AQM, the dark buffers of the Internet are themselves going dark!
UPDATE: ping's (and socket connections) under Verizon FiOS are always 'good',
regardless of any other download (with known queueing) taking place.
|
3. AQM hides where packets are intentionally dropped
|
|
Take a look at the following download graph from Comcast in Maryland.
Why does the download speed tank right around
the two second mark (and for reference, refer to the end of this section for what a
normal download of the same file looks like -- right around 125Mbps)?
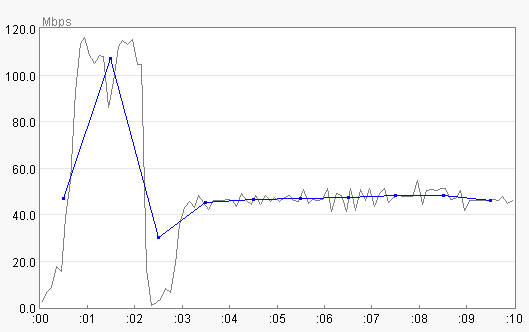
Looking at the raw data reads, there was a very significant pause of 0.266564 seconds
followed by an unusually large data read of 3,478,492 bytes, which given that virtually all other
data reads are a small multiple of the MSS (1460), is (statistically) very indicative of packet loss.
Using
WireShark, the problem was confirmed to be a single lost packet just
after time 1.948974. And this problem is 100% reproducible (clearly the time of the
single lost packet varies, but a single packet is dropped, causing the download speed
to tank).
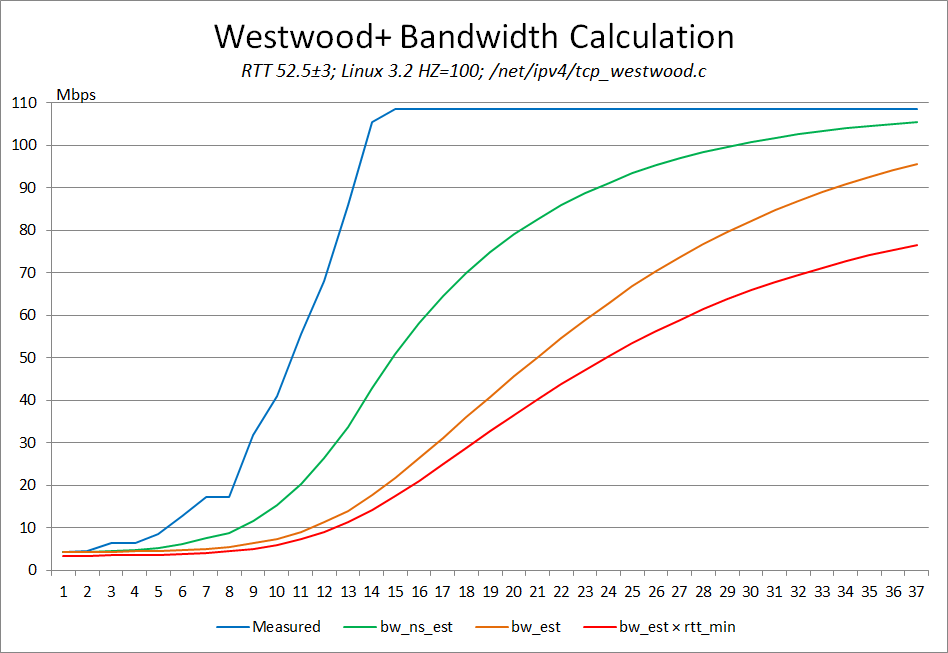
UPDATE: The graph above is not caused by PowerBoost (which Comcast confirmed is no long persent on my connection),
as many people assume, but rather is caused by the interaction between (1) a single dropped packet early in the
connection lifetime, (2) the Westwood+ congestion control algorithm on the server,
whose bandwidth estimate has not yet ramped up (see red line in graph right), and
(3) bufferbloat, causing a rapid increase in RTT times (causing Westwood+ bandwidth
updates to stall) and a packet timeout.
Also, one of the most interesting aspects is that regardless of the size of the
RWIN receive buffeer (be it 800k or 4000k), a single packet is lost.
The RTT between the client and server is around 52.5±3ms.
There are only three networks involved. The ISP (Comcast in Maryland), the middle man (Level3),
and the web hosting company (1and1). All three network companies vehemently deny that they
are responsible for dropping the packet and points the finger at 'the other guy'. Comcast
blames 1and1, and 1and1 blames Cocmast. And the guy in the middle, Level3, claims they can
not be the cause of the lost packet and will NOT investigate unless a trouble ticket is
initiated by 1and1 or Comcast. Stalemate -- No network wants to find the cause of the
lost packet!
UPDATE: The problem is with Comcast or Level3. I have eliminted 1and1 as the problem.
When downloading the file over Comcast and experiencing lost packets, downloading the
same file (at the same time) over Verizon FiOS results in a great download (no lost
packets).
traceroute and ping show absolutely nothing. In fact, they show that the network is 100%
perfect -- always. Great ping times and no lost packets. Ever.
In fact, Comcast and 1and1 are now using AQM as a weapon against end users! The first
thing Comcast and 1and1 ask for are ping and traceroute results. And when these results
show NO lost packets, Comcast and 1and1 (incorrectly) conclude, "The problem can not be us
since your ping/traceroute results prove we are not dropping packets".
They absolutely know better! This is a classic case of flawed logic (that the results
prove the negative) -- there may simply not have been enough pings for the packet loss
to affect ping. Or far more likely, the pings are in a different queue, and
packet loss is happening in other queues.
And yet, run the download speed test again, and a single packet is killed off once again,
which kills the download speed. It has been suggested to me that
just knowing that there is congestion is enough. No, that is not enough -- those people don't
understand the problem to be solved. If you need to avoid the congestion, what do you
change? Do you switch to a new ISP? Do you switch to a new hosting provider? Do you
need to work around a policy decision on the part of a backbone provider? Is there
a peering war going on between Comcast and Level3 in Dallas?
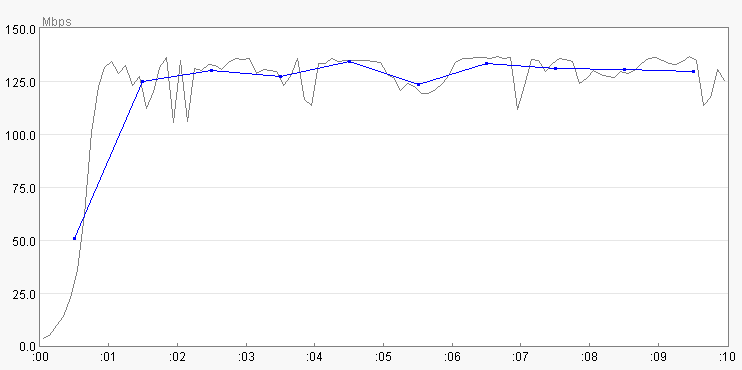
And for reference, here is what the download of the same file looks like with
no dropped packets:
|
4. One solution: Add a "dropped packet notification" to AQM
|
|
Instead of AQM silently dropping a packet, AQM should replace the packet (dropping it)
with a "dropped packet notification" sent to the receiver (not the sender).
One possible implementation is through a new "AQM" ICMP message type, and a "packet
dropped" sub-type. And there are clearly many other ways this notification could
be implemented.
The core underlying goal is: for the network device that successfully receives a packet,
but then actively and intentionally drops that packet, to identify itself to the
receiver.
And before anyone goes off the deep end claiming that this can not be
implemented because the notification adds too much overhead to an already
congested network -- the answer to that is simple: Dropping a single
packet on a TCP connection already has a very substantial (negative) effect
on the TCP connection bandwidth. The TCP connection can absolutely, positively
withstand one extra very small notification packet. Using the chart
above as an example, you would need to (successfully) argue that the network
can handle transferring over 42MB of data after the single dropped packet, but
can not handle transferring 42MB plus one extra very small packet.
To address overhead concerns when tons of packets do have to be dropped,
the notification packets themselves could/should be rate limited, and subject
to AQM (dropping a 'notification packet' does not generate a
notification packet).
|
|